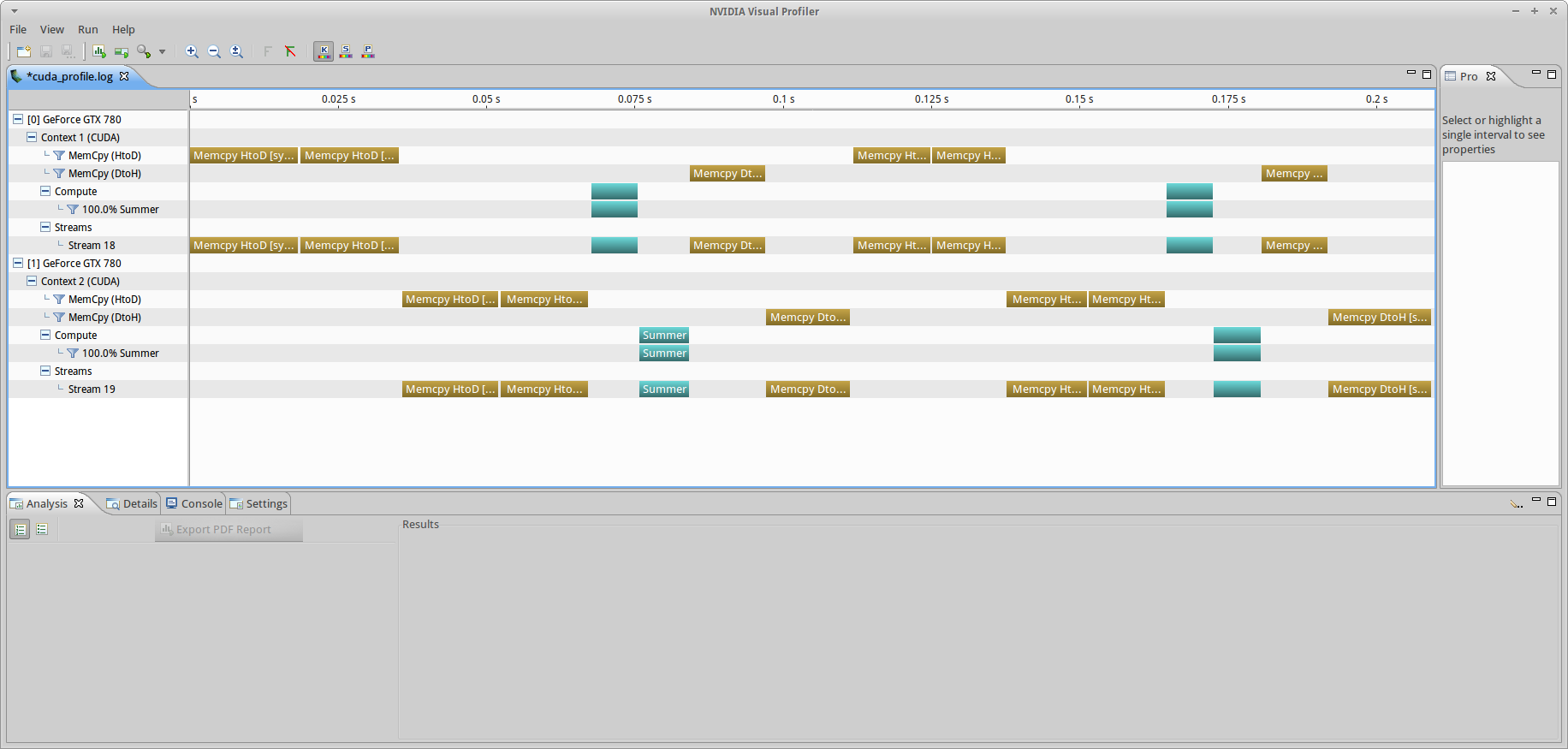
I’m struggling to understand why the execution of OpenCL enqueue* function calls is seemingly sequential in a multi-GPU environment with two independent CommandQueues. I have two GTX 780s. I’m using CUDA SDK 7.0 for the source files and the nvidia 346 driver’s libOpenCL.so.0 .
Here is what I am talking about: http://i.imgur.com/nWXzrLo.png
This code is part of a project I’m working on to showcase the feature set of OpenCL. The kernel is blindingly simple, it accesses one value each from READ_ONLY buffers, sums them, and writes them to a WRITE_ONLY buffer. When there are multiple devices, the original vector is cut in pieces and the iterators are offset by the size of the vector divided by the number of devices. To compile and execute my code, please do the following
git clone https://github.com/stevenovakov/learnOpenCL.git
git checkout simple_events
$ make clean program
please use the branch simple_events and take a look at how the environment is constructed in oclenv.cc and how the calls are executed in main.cc. You can use my scripts to do profiling by calling the program with
$ ./profiling.sh <args>
I suggest args like
$ ./profiling.sh -datasize=50 -chunksize=25
for nice and fast execution. When that completes, look at the data with
$ nvvp cuda_profile.log
please see the README for more detailed compilation/execution/profiling instructions.
I would expect the profiler to put out something like this: http://imgur.com/fsYiihk (excuse the paint hackjob) with only some minimal time required for the host to execute looping/etc between enqueue* calls. The commandqueues are out-of-order and the enqueue* calls are only dependent on events. This has been plaguing me for some time and I would appreciate any help. Thanks!
NOTE: I also tried an approach with multiple contexts (one per device). And generated exactly the same type of output. If you want to try this, check out the single_thread_multi_context branch and run it the same way:
$ ./profiling.sh -datasize=50 -chunksize=25
you will have to remove empty context logs from cuda_profile.sh for it to display properly in nvvp.
{kind=link}
{kind=link}