This is likely the first part of 2 posts related to some trouble I have involving an FFT signal cross correlation module I’m creating, (makes use of circular convolution theorem, etc etc). I’d like to just confirm that the following scheme will ensure that particular recursion levels of FFT butterfly computation are finished before the next level starts and that the buffers containing the data are fully written to/done with. So the circular correlation/convolution involves an FFT, a vector-wise inner product and then an IFFT.
Because of this scheme, I have no kernels which order the data in bit-reversed index order. The forward FFT kernel produces a bit-reversed-order FFT and, after the inner products, the IFFT just uses this result to compute a natural order solution.
I should mention I have multiple GPU’s.
Anyways, here is a pseudo-code representation of what is going on for every FFT/IFFT, (access/operation algorithms are equivalent, other than conjugated twiddle factors, the normalization kernel comes later:
for numDevices:
data -> buffers
buffers -> kernel arguments
for fftRecursionLevels:
for numDevices:
recursionLevel -> kernel arguments
deviceCommandQueue -> enqueueNDRangeKernel
deviceCommandQueue -> flush()
for numDevices:
deviceCommandQueue -> finish()
Can I get away with that? As far as I understand finish() is a blocking function and that very last for loop would not complete until every kernel is finished computing across its global range, (here fftSize / 2, see any literature on Radix-2 butterfly operations), and, for bonus points, some of the kernels are executing already due to flush() while I’m enqueueing the remaining kernels.
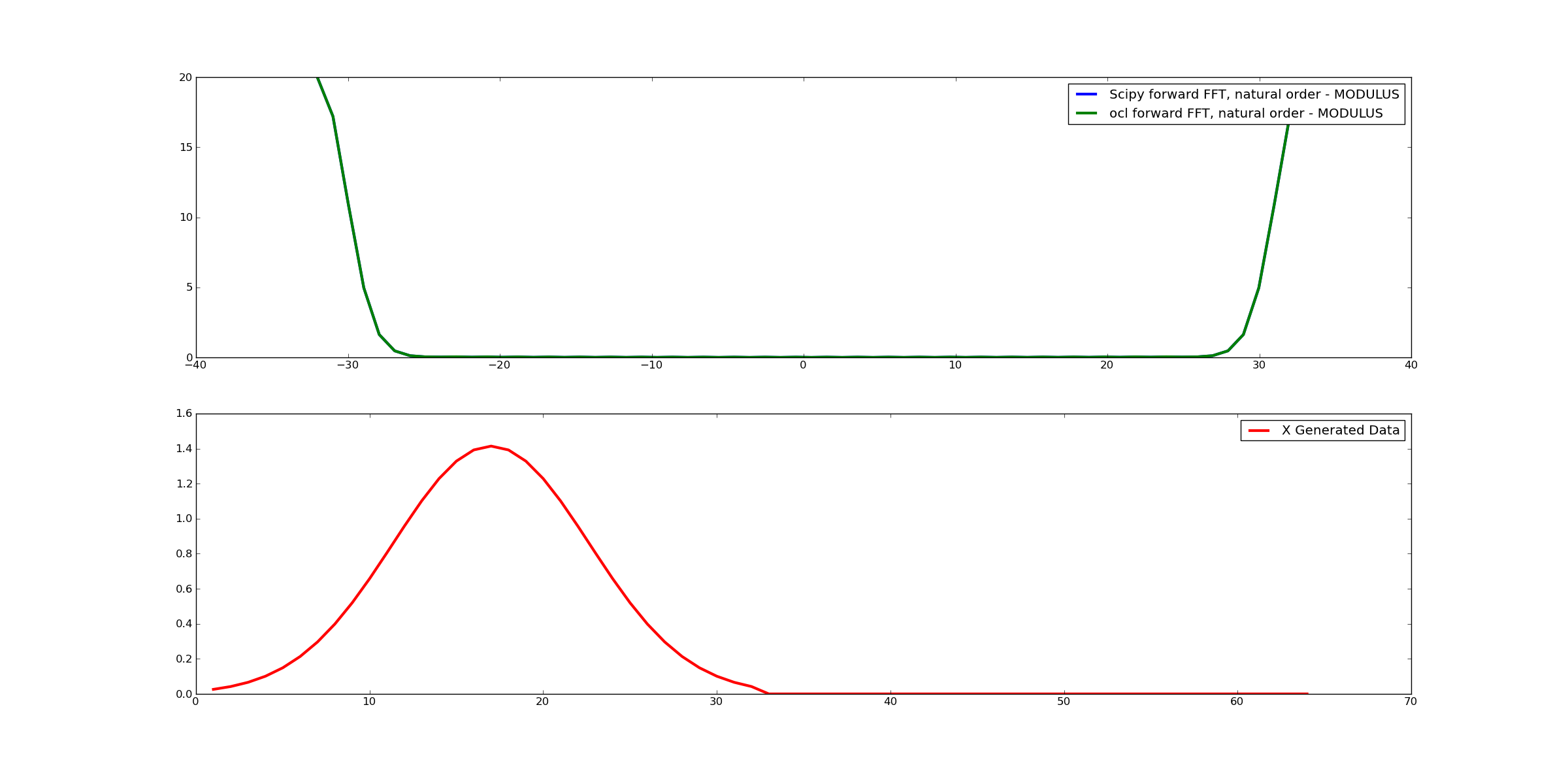
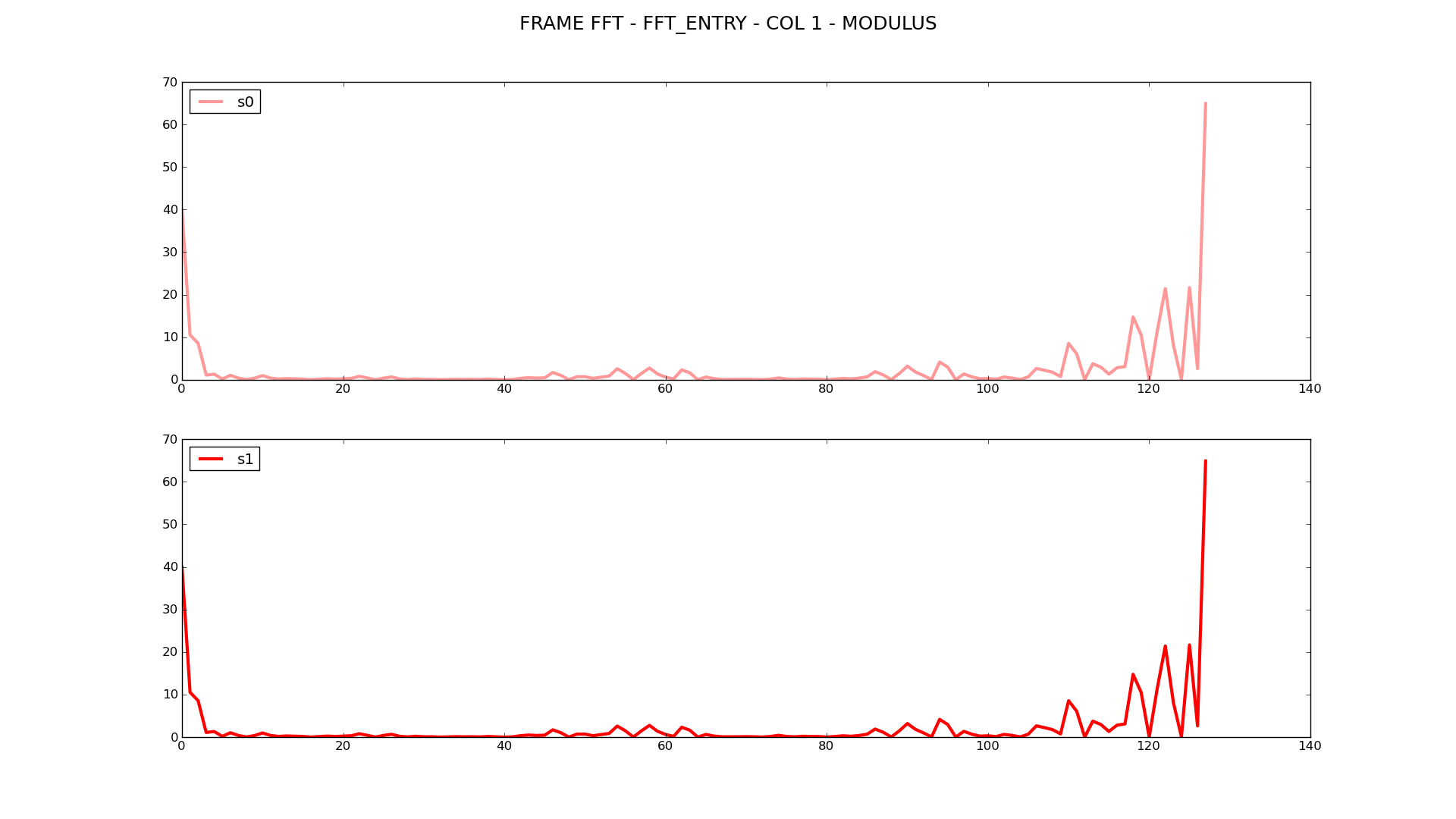
Overall, I’m geting some funky/garbage results using openCL/c++ for this particular software. I have implemented the full data pipeline in python, (the algorithm is, “topologically equivalent” if you will, obviously there is no host<–>device buffer/instructions w/ the python), and simulated how the kernel should run and it produces IDENTICAL results to when I use scipy.fftpack modules and just operate on the signal data vectors.
Thanks in advance.